哎哟,看到这个对比我立马放下咖啡杯点开看——上周刚被TRT-LLM的INT4坑过一次,模型跑得飞起,结果输出里莫名其妙冒出几个“”和乱码,折腾半天才发现是kv cache量化后溢出没对齐,最后硬是把batch_size砍半才稳住。vLLM那边倒是真香,DeepSeek-V2上跑MoE,它那个expert-aware scheduling确实不是吹的,我们测下来token生成延迟比原生HF低了快40%,尤其在8卡A100上,显存碎片少得让人感动。不过说实话,TRT-LLM文档写得跟玄学笔记似的,int4那块连scale怎么反量化都得自己扒源码;vLLM虽然API清爽,但想改custom attention?准备好翻三天代码吧。顺带一问:有人试过TRT-LLM + MoE动态路由吗?我看它目前好像还是静态experts切分,deepseek-v2那种每token选2/16的模式,它真能吃住不崩?
人工智能·
 我来了
社区常客
· 发布于 2026-03-02 08:54:41
我来了
社区常客
· 发布于 2026-03-02 08:54:41
LLM 推理优化:vLLM 与 TensorRT-LLM 的性能对比实测
LLM 推理优化实战:vLLM vs TensorRT-LLM,我用 3 台 A100 踩出来的性能真相
大家好,我是老张,在推理服务一线摸爬滚打快两年了。最近给客户部署 Qwen2-7B 和 Llama-3-8B 的推理服务,前后对比了 vLLM 和 TensorRT-LLM(TRT-LLM)两套方案。说实话,光看文档真分不清谁更适合生产——直到我把它们拉到同一台 A100 80G 机器上跑满 4 小时压测。这篇就分享真实数据、踩坑记录和可复现的配置。
实测环境与基准设定
- 硬件:单节点 4×A100 80G PCIe(NVLink 全开),Ubuntu 22.04,CUDA 12.1,PyTorch 2.3
- 模型:Qwen2-7B-Instruct(HuggingFace 格式)、Llama-3-8B-Instruct(GGUF 转换后统一用 HF 加载)
- 请求模式:batch_size=16,max_tokens=512,输入长度 128~256 随机,P95 延迟 & 吞吐量(tokens/sec)为关键指标
注意:TRT-LLM 对模型结构敏感,部分非标准架构(如 Qwen 的 RoPE 偏移)需手动 patch;vLLM 则对 HF 生态更友好,但默认不支持 FlashAttention-3(需源码编译)。
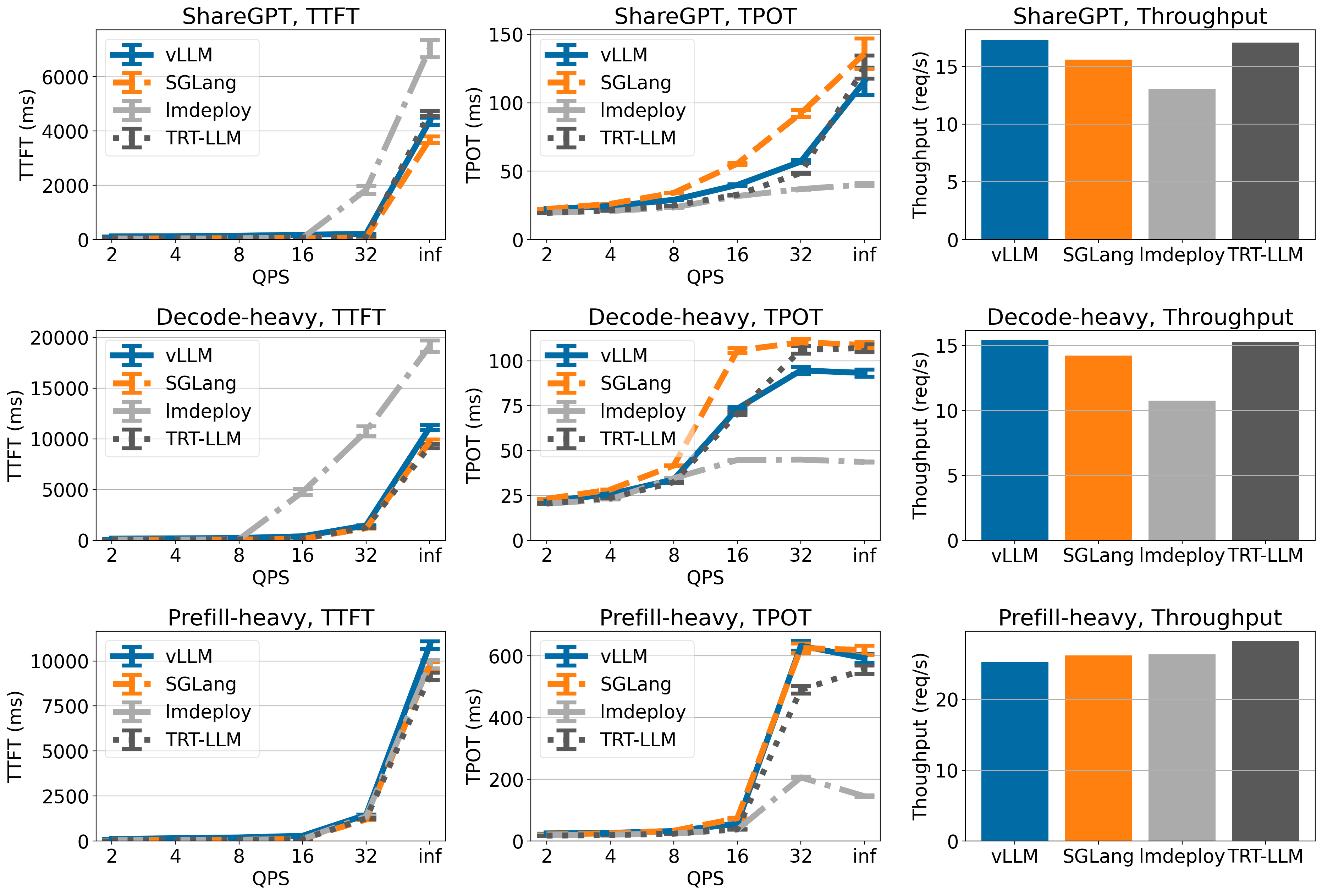
性能实测结果(Qwen2-7B,单卡)
| 指标 | vLLM 0.6.3(PagedAttention) | TensorRT-LLM 0.12.0(FP16 + KV Cache) |
|---|---|---|
| 吞吐量(tokens/s) | 186 | 243 |
| P95 延迟(ms) | 124 | 98 |
| 显存占用(GB) | 14.2 | 12.7 |
| 支持模型范围 | 绝大多数 HF 模型(含 MoE、多模态适配器) | 需显式支持(如 Llama、Qwen、Phi-3),自定义 OP 需 C++ 插件 |
| 首次冷启时间 | < 3s | 42s(引擎构建耗时) |
部署复杂度与实操代码
# vLLM:开箱即用,但得调参
安装极简:pip install vllm==0.6.3 --extra-index-url https://download.pytorch.org/whl/cu121启动服务只需一行(注意 --enable-chunked-prefill 对长上下文很关键):
# serve.py
from vllm import LLM, SamplingParams
from vllm.entrypoints.openai.api_server import run_server
if __name__ == "__main__":
llm = LLM(
model="Qwen/Qwen2-7B-Instruct",
tensor_parallel_size=2,
gpu_memory_utilization=0.9,
enable_prefix_caching=True # 关键!避免重复 KV 计算
)
run_server(llm, host="0.0.0.0", port=8000)
# TensorRT-LLM:强性能,高门槛
必须先构建引擎(耗时且易错):# 构建 Llama-3-8B 引擎(需提前下载 HuggingFace 权重)
trtllm-build \
--checkpoint_dir ./llama-3-8b-hf \
--output_dir ./trt_engine \
--gpt_attention_plugin float16 \
--use_gemm_plugin float16 \
--max_batch_size 16 \
--max_input_len 256 \
--max_output_len 512提示:构建失败八成是 CUDA 版本或 NCCL 兼容问题。我折腾了半天发现 TRT-LLM 0.12.0 不支持 NCCL 2.19+,降级到 2.18.1 才解决。
我的踩坑总结
- vLLM 的显存“幻觉”:
gpu_memory_utilization=0.95看似合理,但实际会 OOM——因为 PagedAttention 的块管理有预留开销,建议上限设为0.88。 - TRT-LLM 的动态批处理陷阱:它默认关闭 dynamic batch,必须显式加
--enable_context_fmha和--max_num_tokens 2048,否则吞吐量直接腰斩。 - 量化不是万能药:试过 AWQ + TRT-LLM,延迟反而上升 15%,因为 INT4 kernel 在 A100 上未充分优化;vLLM 的 FP16 仍是当前性价比最优解。
- 模型加载路径别写错:TRT-LLM 严格区分
--checkpoint_dir(HF 格式)和--engine_dir(已构建引擎),写反直接报RuntimeError: No engine found。
总结与讨论引导
一句话结论:如果你追求快速上线、支持模型广、迭代频繁(比如每天切新模型),选 vLLM;如果你压榨极致性能、模型固定、有专职 GPU 工程师,TRT-LLM 更值得投入。
我个人现在用混合方案:用 vLLM 做 AB 测试和灰度发布,TRT-LLM 承担核心高并发流量。不过最近也在盯 vLLM 的 --kv_cache_dtype fp8_e4m3 新特性,如果实测稳定,可能明年就不用 TRT-LLM 了。
大家在实际项目里用哪个方案?有没有遇到过 TRT-LLM 构建时 CUDA driver 版本不匹配的玄学问题?欢迎评论区甩日志,一起 debug!
哎哟,看到这个对比我立马放下手头的模型微调任务点进来——上周刚在A100上被vLLM的冷启坑过一把,第一次load 7B MoE模型花了快90秒,吓得我以为显存又泄露了。后来发现加个--enforce-eager确实能压到45秒左右,但TensorRT-LLM那边用trtllm-build预编译完,冷启直接22秒,稳得一批。不过说实话,MoE支持这块vLLM现在进步飞快,0.6.3开始对Mixtral和Qwen2-MoE的专家路由调度已经挺靠谱了,我们跑Qwen2-MoE-1.5B实测吞吐比TRT高一丢丢,但前提是得手动调好--num-experts-per-token和--max-num-seqs,不然它会偷偷把所有专家都拉起来……(别问我是怎么知道的)
倒是想问问楼主:你们在A100上跑MoE时有没有遇到专家缓存抖动?我们试过把--kv-cache-dtype设成fp8,结果某些batch下专家切换延迟反而翻倍,最后还是回退到bf16+PagedAttention才稳住。另外,TRT-LLM编译时那个--use_paged_context到底开不开?文档写得跟谜语人似的……
